숏폼을 만들 때 제일 볼륨 있는 항목은 아마도 '추천' 일 것이다.
Collaborative Filtering 과 Content-Based Filtering를 어떤 비율로 배합하고 이 중 몇개를 뽑아 낼 지, 사용하는 기술 스택은 뭐가 있는 지, 대대적인 조사가 필요했다.
다행이게도 트위터가 오픈 소스로 추천 알고리즘을 깃허브에 공유해주었기 때문에 많은 분석글을 참조할 수 있었다.
따라서 트위터의 추천알고리즘을 사전 학습 하기로 했다.
1. 추천 알고리즘 아키텍쳐
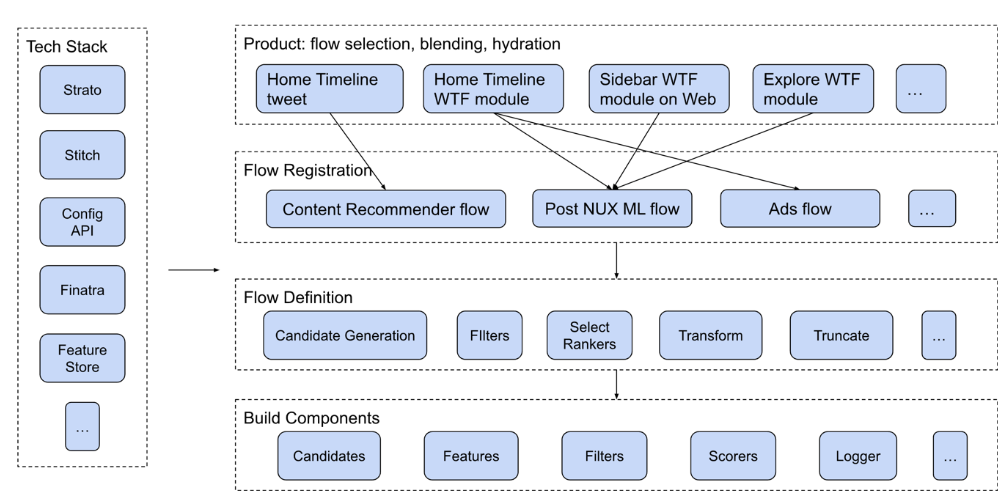
1. Tech Stack (기술 스택): 사용되는 기술 스택이 나열 → 추천 시스템이 작동하기 위해 필요한 기본 구성 요소로 사용
Strato: 데이터 저장 및 관리 플랫폼으로, 추천 시스템의 데이터 레이어
Stitch: 데이터를 수집하거나 통합하는 데 사용하는 도구
Config API: 구성 설정을 관리하는 API로, 추천 시스템의 유연성을 높이기 위해 사용
Finatra: Twitter에서 사용하는 경량 HTTP 서버 및 RPC 프레임워크
Feature Store: 추천 시스템이 사용할 피처(특징)를 저장하는 시스템
2. Product (추천 결과가 사용되는 제품) :추천 시스템의 결과물이 사용되는 구체적인 사용처(?)가 나열
Home Timeline tweet: 홈 타임라인에서 트윗을 추천하는 모듈.
Home Timeline WTF module: "Who to Follow (WTF)" 같은 팔로우 추천 모듈.
Sidebar WTF module on Web: 웹 버전의 사이드바에서 팔로우 추천을 위한 모듈.
Explore WTF module: 탐색 탭에서 팔로우 추천을 위한 모듈
3. Flow Registration (추천 흐름 등록) :추천 시스템의 파이프라인이 등록되는 단계
→ 다양한 파이프라인을 정의해서 이를 제품 모듈에 연결하는 작업
Content Recommender Flow: 사용자에게 적합한 콘텐츠를 추천하는 흐름.
Post NUX ML Flow: 사용자 온보딩 이후 머신러닝(ML)을 통해 적합한 콘텐츠를 추천하는 흐름.
Ads Flow: 광고 추천과 관련된 흐름.
4. Flow Definition (추천 흐름 정의): 추천 시스템의 핵심 로직이 설계되는 부분
Candidate Generation: 추천 후보 데이터를 생성하는 단계.
Filters: 적합하지 않은 후보를 필터링하는 단계.
Select Rankers: 후보를 우선순위에 따라 정렬하는 단계.
Transform: 추천 데이터의 형태를 조정.
Truncate: 최종적으로 사용자에게 표시할 데이터의 크기를 제한.
.
5. Build Components (추천 시스템 구성 요소) : 최적의 추천 결과를 생성하는 핵심 기능을 담당
Candidates: 추천할 수 있는 데이터 후보군.
Features: 머신러닝에서 사용하는 피처(특징) 데이터.
Filters: 부적합한 데이터를 걸러내는 필터.
Scorers: 각 후보에 점수를 매기는 평가 모듈.
Logger: 추천 시스템의 작동 과정을 기록하는 로거.
이 단계는 추천 시스템이 데이터를 처리하고
전체 흐름
<개발자> <----------------------------------------------------------------------------> <사용자>
Build Component Flow Definitionm Flow Registration Product
CandidateUser.scalar 요약: Twitter의 추천 시스템에서 추천 후보 데이터를 표현하는 핵심 데이터 모델
추천 점수, 추천 이유, 소스 정보 등 다양한 정보를 포함 둥, Thrift 객체로 변환하여 다른 시스템과 통신하거나 로그로 저장할 수 있음. 또한, 추천 점수 추가, 팔로우 증거 설정 등 추천 관련 주요 기능을 제공중.
package com.twitter.follow_recommendations.common.models
import com.twitter.follow_recommendations.logging.{thriftscala => offline}
import com.twitter.follow_recommendations.{thriftscala => t}
import com.twitter.hermit.constants.AlgorithmFeedbackTokens
import com.twitter.ml.api.thriftscala.{DataRecord => TDataRecord}
import com.twitter.ml.api.util.ScalaToJavaDataRecordConversions
import com.twitter.timelines.configapi.HasParams
import com.twitter.timelines.configapi.Params
import com.twitter.product_mixer.core.model.common.UniversalNoun
import com.twitter.product_mixer.core.model.common.identifier.CandidateSourceIdentifier
trait FollowableEntity extends UniversalNoun[Long]
trait Recommendation
extends FollowableEntity
with HasReason
with HasAdMetadata
with HasTrackingToken {
val score: Option[Double]
def toThrift: t.Recommendation
def toOfflineThrift: offline.OfflineRecommendation
}
case class CandidateUser(
override val id: Long,
override val score: Option[Double] = None,
override val reason: Option[Reason] = None,
override val userCandidateSourceDetails: Option[UserCandidateSourceDetails] = None,
override val adMetadata: Option[AdMetadata] = None,
override val trackingToken: Option[TrackingToken] = None,
override val dataRecord: Option[RichDataRecord] = None,
override val scores: Option[Scores] = None,
override val infoPerRankingStage: Option[scala.collection.Map[String, RankingInfo]] = None,
override val params: Params = Params.Invalid,
override val engagements: Seq[EngagementType] = Nil,
override val recommendationFlowIdentifier: Option[String] = None)
extends Recommendation
with HasUserCandidateSourceDetails
with HasDataRecord
with HasScores
with HasParams
with HasEngagements
with HasRecommendationFlowIdentifier
with HasInfoPerRankingStage {
val rankerIdsStr: Option[Seq[String]] = {
val strs = scores.map(_.scores.flatMap(_.rankerId.map(_.toString)))
if (strs.exists(_.nonEmpty)) strs else None
}
val thriftDataRecord: Option[TDataRecord] = for {
richDataRecord <- dataRecord
dr <- richDataRecord.dataRecord
} yield {
ScalaToJavaDataRecordConversions.javaDataRecord2ScalaDataRecord(dr)
}
val toOfflineUserThrift: offline.OfflineUserRecommendation = {
val scoringDetails =
if (userCandidateSourceDetails.isEmpty && score.isEmpty && thriftDataRecord.isEmpty) {
None
} else {
Some(
offline.ScoringDetails(
candidateSourceDetails = userCandidateSourceDetails.map(_.toOfflineThrift),
score = score,
dataRecord = thriftDataRecord,
rankerIds = rankerIdsStr,
infoPerRankingStage = infoPerRankingStage.map(_.mapValues(_.toOfflineThrift))
)
)
}
offline
.OfflineUserRecommendation(
id,
reason.map(_.toOfflineThrift),
adMetadata.map(_.adImpression),
trackingToken.map(_.toOfflineThrift),
scoringDetails = scoringDetails
)
}
override val toOfflineThrift: offline.OfflineRecommendation =
offline.OfflineRecommendation.User(toOfflineUserThrift)
val toUserThrift: t.UserRecommendation = {
val scoringDetails =
if (userCandidateSourceDetails.isEmpty && score.isEmpty && thriftDataRecord.isEmpty && scores.isEmpty) {
None
} else {
Some(
t.ScoringDetails(
candidateSourceDetails = userCandidateSourceDetails.map(_.toThrift),
score = score,
dataRecord = thriftDataRecord,
rankerIds = rankerIdsStr,
debugDataRecord = dataRecord.flatMap(_.debugDataRecord),
infoPerRankingStage = infoPerRankingStage.map(_.mapValues(_.toThrift))
)
)
}
t.UserRecommendation(
userId = id,
reason = reason.map(_.toThrift),
adImpression = adMetadata.map(_.adImpression),
trackingInfo = trackingToken.map(TrackingToken.serialize),
scoringDetails = scoringDetails,
recommendationFlowIdentifier = recommendationFlowIdentifier
)
}
override val toThrift: t.Recommendation =
t.Recommendation.User(toUserThrift)
def setFollowProof(followProofOpt: Option[FollowProof]): CandidateUser = {
this.copy(
reason = reason
.map { reason =>
reason.copy(
accountProof = reason.accountProof
.map { accountProof =>
accountProof.copy(followProof = followProofOpt)
}.orElse(Some(AccountProof(followProof = followProofOpt)))
)
}.orElse(Some(Reason(Some(AccountProof(followProof = followProofOpt)))))
)
}
def addScore(score: Score): CandidateUser = {
val newScores = scores match {
case Some(existingScores) => existingScores.copy(scores = existingScores.scores :+ score)
case None => Scores(Seq(score))
}
this.copy(scores = Some(newScores))
}
}
object CandidateUser {
val DefaultCandidateScore = 1.0
// for converting candidate in ScoringUserRequest
def fromUserRecommendation(candidate: t.UserRecommendation): CandidateUser = {
// we only use the primary candidate source for now
val userCandidateSourceDetails = for {
scoringDetails <- candidate.scoringDetails
candidateSourceDetails <- scoringDetails.candidateSourceDetails
} yield UserCandidateSourceDetails(
primaryCandidateSource = candidateSourceDetails.primarySource
.flatMap(AlgorithmFeedbackTokens.TokenToAlgorithmMap.get).map { algo =>
CandidateSourceIdentifier(algo.toString)
},
candidateSourceScores = fromThriftScoreMap(candidateSourceDetails.candidateSourceScores),
candidateSourceRanks = fromThriftRankMap(candidateSourceDetails.candidateSourceRanks),
addressBookMetadata = None
)
CandidateUser(
id = candidate.userId,
score = candidate.scoringDetails.flatMap(_.score),
reason = candidate.reason.map(Reason.fromThrift),
userCandidateSourceDetails = userCandidateSourceDetails,
trackingToken = candidate.trackingInfo.map(TrackingToken.deserialize),
recommendationFlowIdentifier = candidate.recommendationFlowIdentifier,
infoPerRankingStage = candidate.scoringDetails.flatMap(
_.infoPerRankingStage.map(_.mapValues(RankingInfo.fromThrift)))
)
}
def fromThriftScoreMap(
thriftMapOpt: Option[scala.collection.Map[String, Double]]
): Map[CandidateSourceIdentifier, Option[Double]] = {
(for {
thriftMap <- thriftMapOpt.toSeq
(algoName, score) <- thriftMap.toSeq
} yield {
CandidateSourceIdentifier(algoName) -> Some(score)
}).toMap
}
def fromThriftRankMap(
thriftMapOpt: Option[scala.collection.Map[String, Int]]
): Map[CandidateSourceIdentifier, Int] = {
(for {
thriftMap <- thriftMapOpt.toSeq
(algoName, rank) <- thriftMap.toSeq
} yield {
CandidateSourceIdentifier(algoName) -> rank
}).toMap
}
}